The ChaosIQ Reliability Workflow¶
ChaosIQ provides a Reliability Workflow. The Reliability Workflow’s job is to help you proactively verify your system to gain insights into its reliability so that you can then prioritize and track work on improving that reliability alongside the regular work that you need to do on features.
There are lots of good reasons to verify your system. You might be worried about surprise downtime and looking to try to anticipate and prepare better for incidents. You might also be curious as to how your system might respond to challenging conditions, and want to explore that before your users do. In a nutshell you want to verify your system because you care about your users’ experience, and specifically about the reliability of that experience.
With ChaosIQ, the goal of system verification is not only to show the impact that various conditions might have on your users happiness but to also turn those insights into prioritized, meaningful actions for improving a system’s reliability. ChaosIQ brings this System Reliability Workflow to life with Objectives, Verifications, Insights and Action Items:
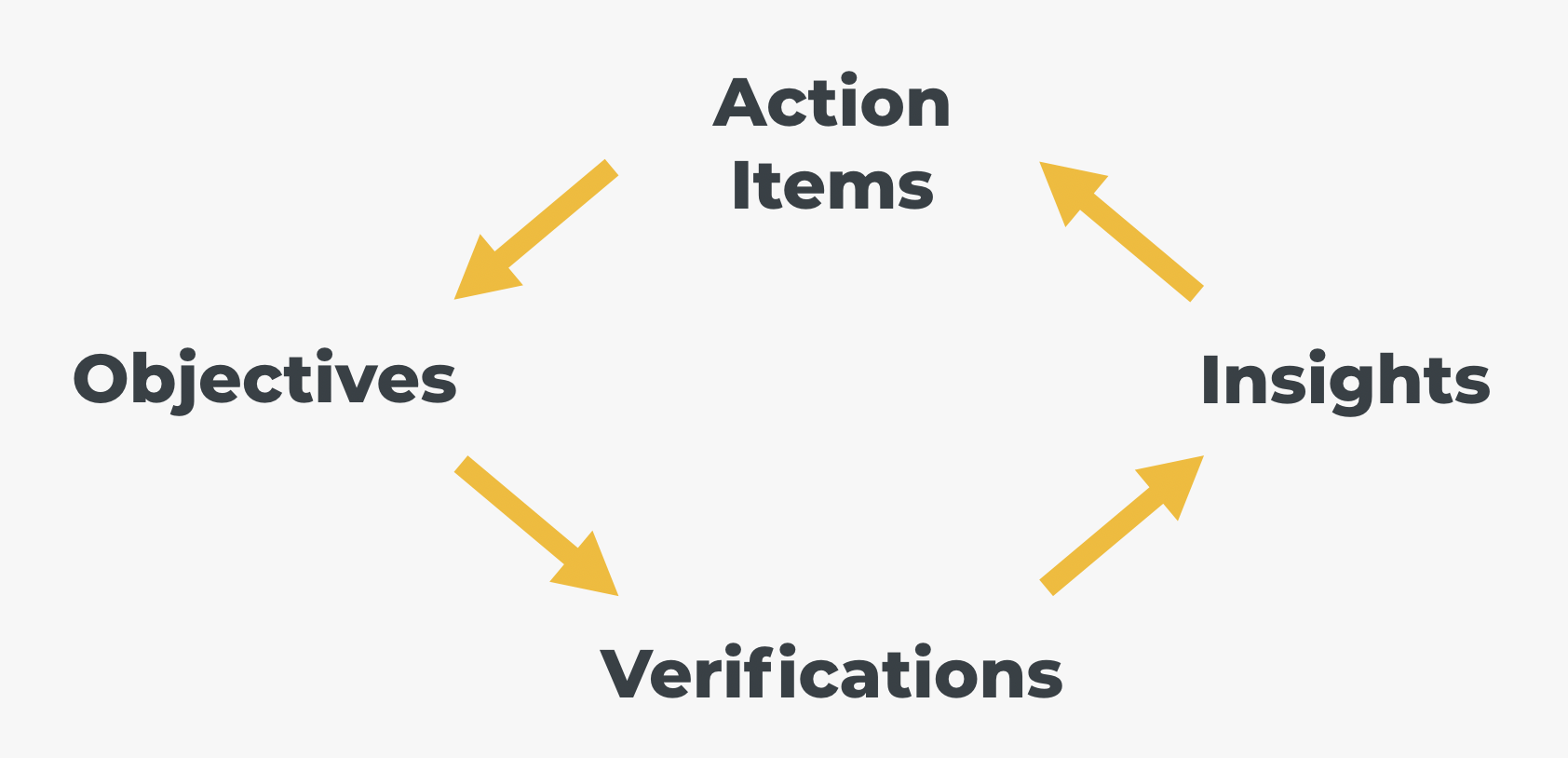
Objectives and Measurements¶
Objectives are literally things you care about. If you care about it, and can measure it, then it’s an objective.
You might care that your homepage is available 99.9% of the time. You might care that your database is able to respond to a particular query under an amount of time. Or you might care that your users can interact with your system, perform some system function, 99.999% of the time as it’s super-critical! These are all Objectives, and they frame what’s important to you about your system. A good set of Objectives represents a great high-level description of how your system aims to behave, from your perspective, in order to make your users happy.
However, an Objective is not particularly useful unless it can be measured. Objectives can be measured in lots of different ways, often in combination, to give you some confidence that an Objective, at a given moment, is being met:
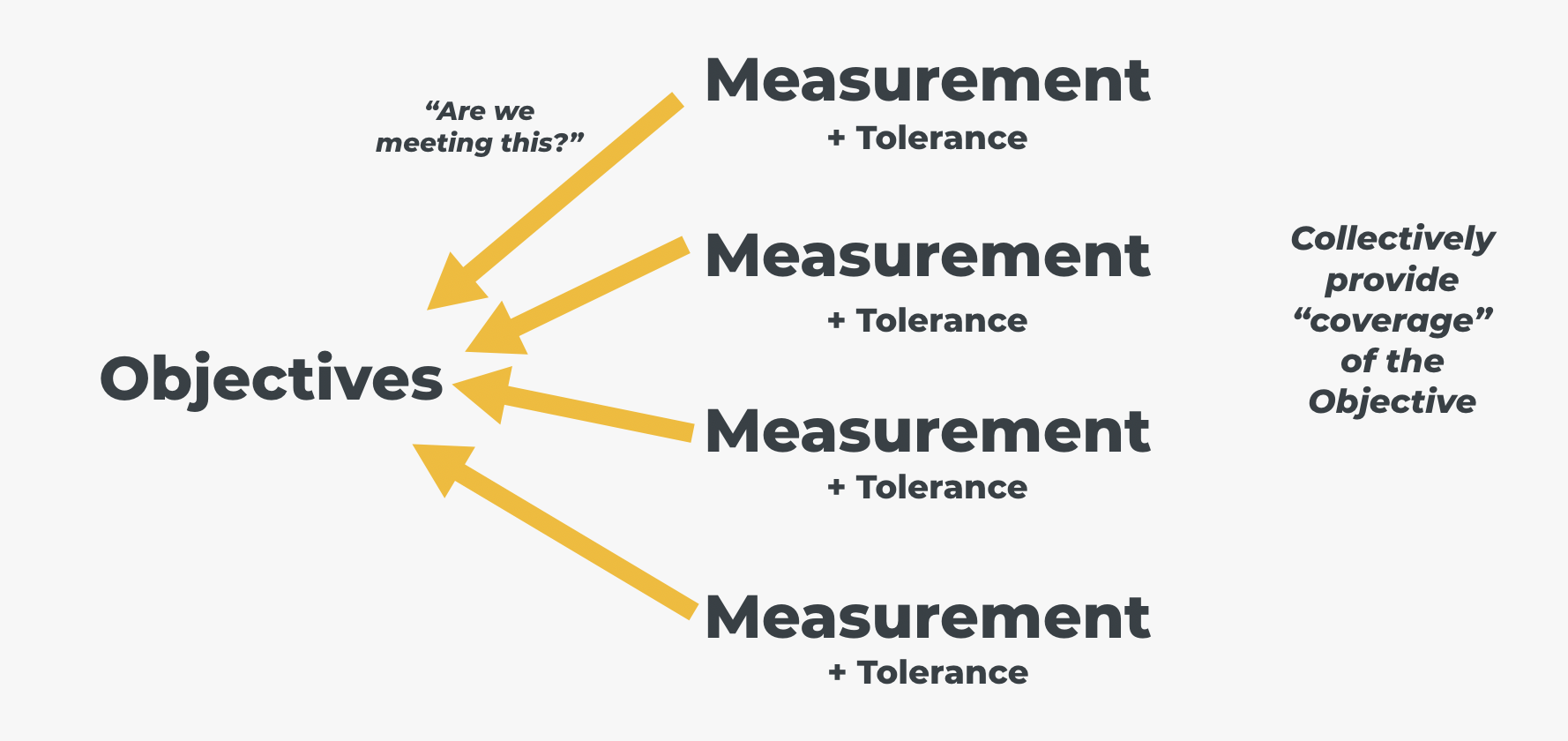
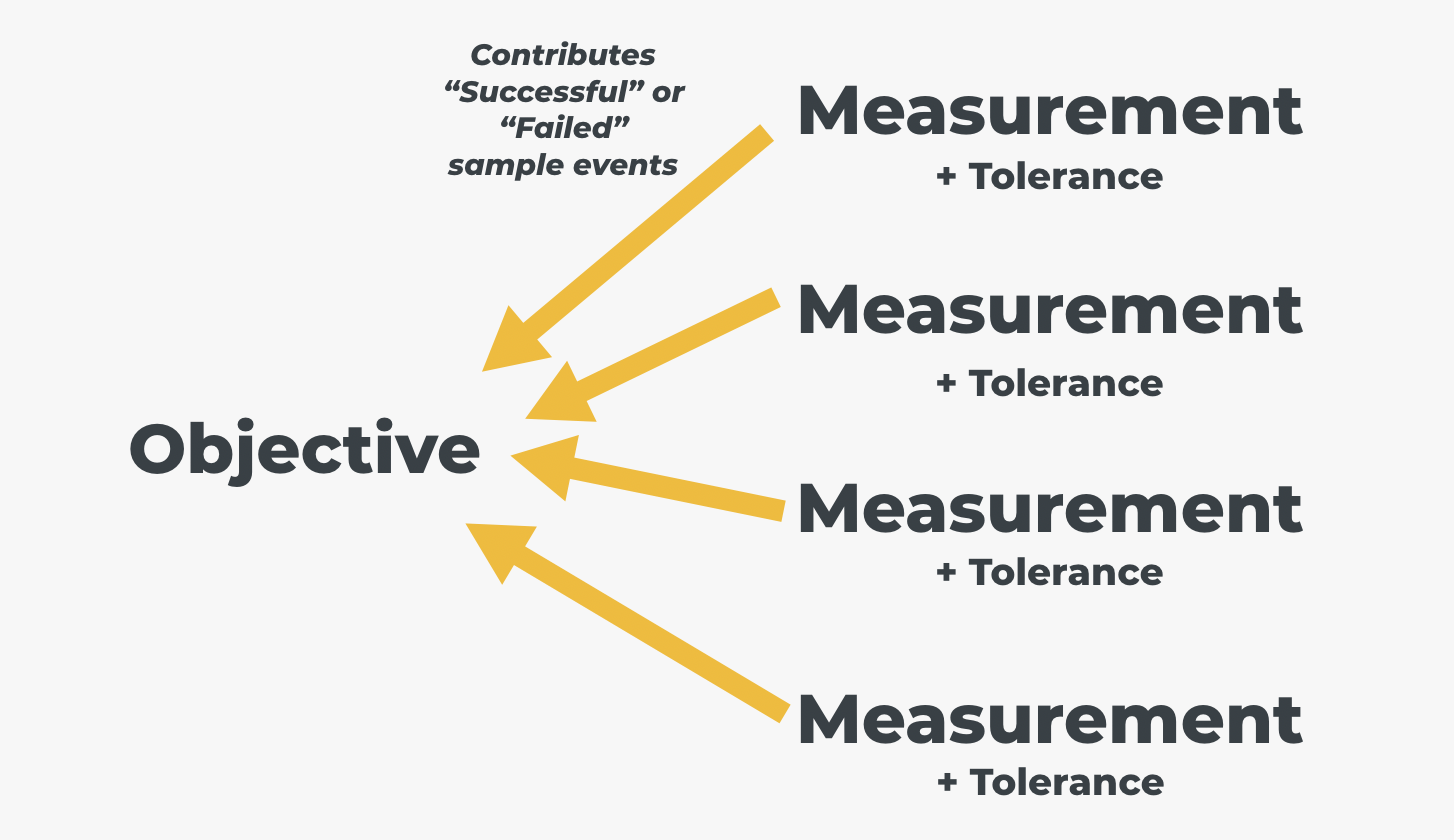
The job of a measurement, or combination of measurements, is to be able provide a sample, an event, that is either “successful” or “failing” at a given moment in time. For example, you might measure that the response time for your homepage is within a tolerable time bracket at a given moment and, if it is within that tolerance, then it is a “successful” sample event. If the measurement shows that the homepage URL does not respond in the tolerated time, then the sample event would be designated “failed”:
The combination of Objectives and their corresponding measurements provides a shared understanding of how your system needs to behave in order to keep your users happy. This is the all-important framing necessary to then decide what you want to verify in order to see how your Objectives, and your users’ happiness, is affected by your system’s behavior under various conditions. TBD link to where you can define objectives in the Getting Started.
Verifications¶
Verifying an Objective helps you build trust and confidence in how your system will behave under a set of interesting conditions. Those conditions could be behavior such as security intrusions, infrastructure failures, platform failures, application failures, interesting user behavior or even administrative changes. In fact, anything that you can conceive of that could happen to your system could be an interesting scenario to explore if you think there’s a likelihood that it may have an impact on one or more of your system’s Objectives.
In our book, ”Learning Chaos Engineering” by O’Reilly Media, a couple of ways of exploring the conditions you might want to explore are covered. In addition, when you are designing a Verification you have the all-important framing of the overall Objective to help you. The Objective helps you decide and prioritize what verifications to perform that will give you the most effective insights, not least because you may want to perform the verification in production where there is likely more risk from the exploration.
For example, you might decide that you want to verify how your system behaves when:
- A virtual machine fails
- A network starts to lose packets
- A configuration change is made
- A Kubernetes Pod, or collection of pods, fail
- A cluster is starved of resources, such as nodes
- A database begins to respond slowly
The list will go on, and you will almost certainly have your own unique conditions that you’re interested in. This is one of the reasons why ChaosIQ is built on top of the free and open source Chaos Toolkit, which makes ChaosIQ an easily customizable and extendable system verification and chaos engineering environment. You need that flexibility, because your conditions will often be unique to your systems.
The first thing you describe in a Verification is the types of conditions you want to introduce to see how this affects your system’s behaviour in respect of your overall Objective. A verification then needs a description of how it will be executed. While a verification is running it will be capturing your Objective’s measurements throughout, continuously gathering sample events that indicate whether the measurement was successful or failed in reference to the overall Objective:
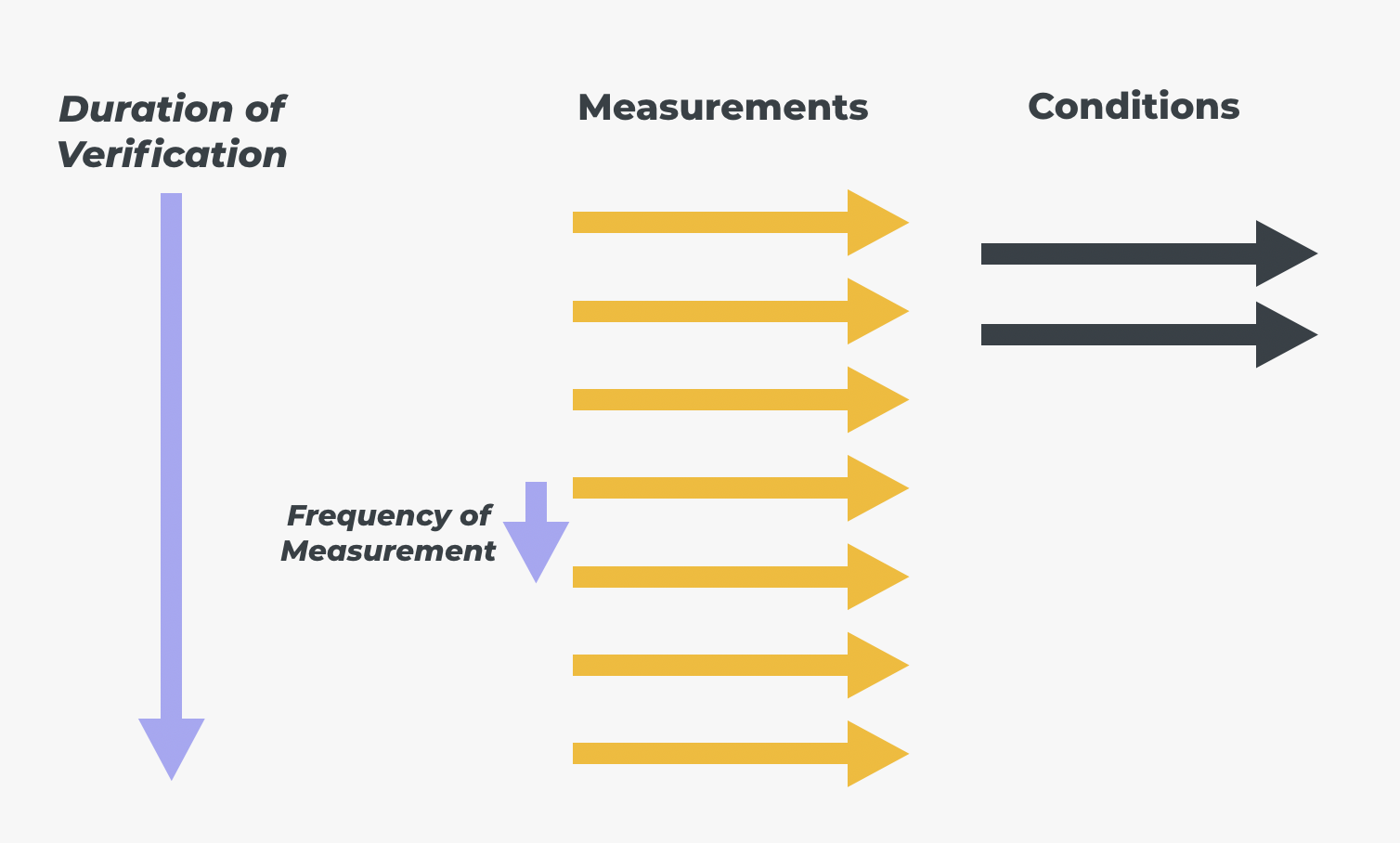
A Verification needs two pieces of information to run itself: Duration and Frequency of Measurement. Duration is self-explanatory, it’s the total duration that you want the verification to be executed for. For example, you might want to run a Verification as the backdrop to a 3-hour GameDay (More on how to do this in a forthcoming article) so, as you’d expect, you’d set the duration of the Verification in this case to 3 hours.
Frequency of Measurement describes just how often you will want to gather a sample event from the system as described by a Measurement for your Objective. You might want to sample every second, or perhaps sampling a measurement every 10 minutes will give you the fidelity you’re looking for. As you run your Verification, all of the data captured by your Measurements’ sample events are collated for interpretation into Insights.
Insights¶
When your Verification has been executed the resulting, potentially large, set of data collated from all the sample event measurements is captured and made available to you. This timeline of event samples in its raw form can be useful but the most common first step is to try to assess what impact on your Objective was seen by those measurements during your verification’s execution. This insight is called the “Objective Impact”.
The “Objective Impact” insight is a calculation based on the duration of the verification and how many failed sample events were measured. The insight gives you an extrapolated indicator of what size of impact the conditions of your verification have on your Objective. This information is key to then decide whether the impact is so minor that your system survived just fine, or whether it’s actually time to assemble your teams and look to the next stage of the workflow: Action Items.
Action Items (coming soon)¶
Insights give you the information you and your teams need to decide what to do to improve your system’s reliability. The insights are framed by the objectives you care about and so you have everything you need to be able to understand and prioritize what should be done and when. What should be done and when are Action Items.
Action Items are how you describe what system reliability improvements you are going to work on. You describe them in ChaosIQ while you analyze the insights from your Verifications. Then track their progress and eventually impacts on future Verification executions. ChaosIQ integrates with the systems you normally use to capture, prioritize and track your work, i.e. issue trackers. ChaosIQ mirrors Action Items as issues in your regular toolset so you can work on this reliability work and its progress is mirrored back into ChaosIQ.
Action Items close the learning loop of the System Verification workflow. Each time you and your teams create new Verifications and explore more and more insights, you will describe and action more reliability improvements balancing your need to innovate at speed with the need to provide a system your users can rely on.